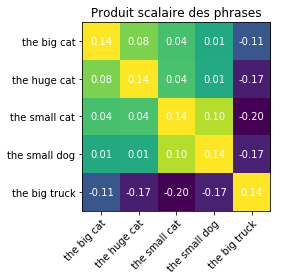
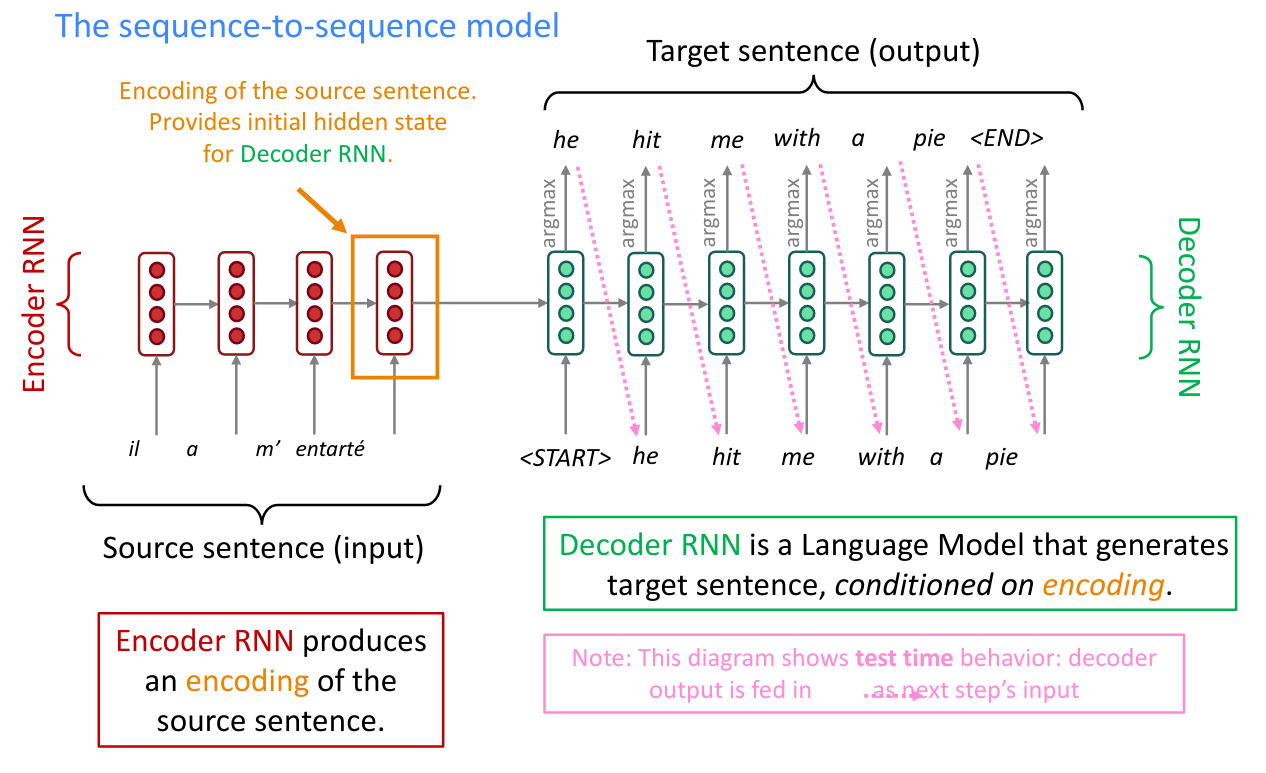
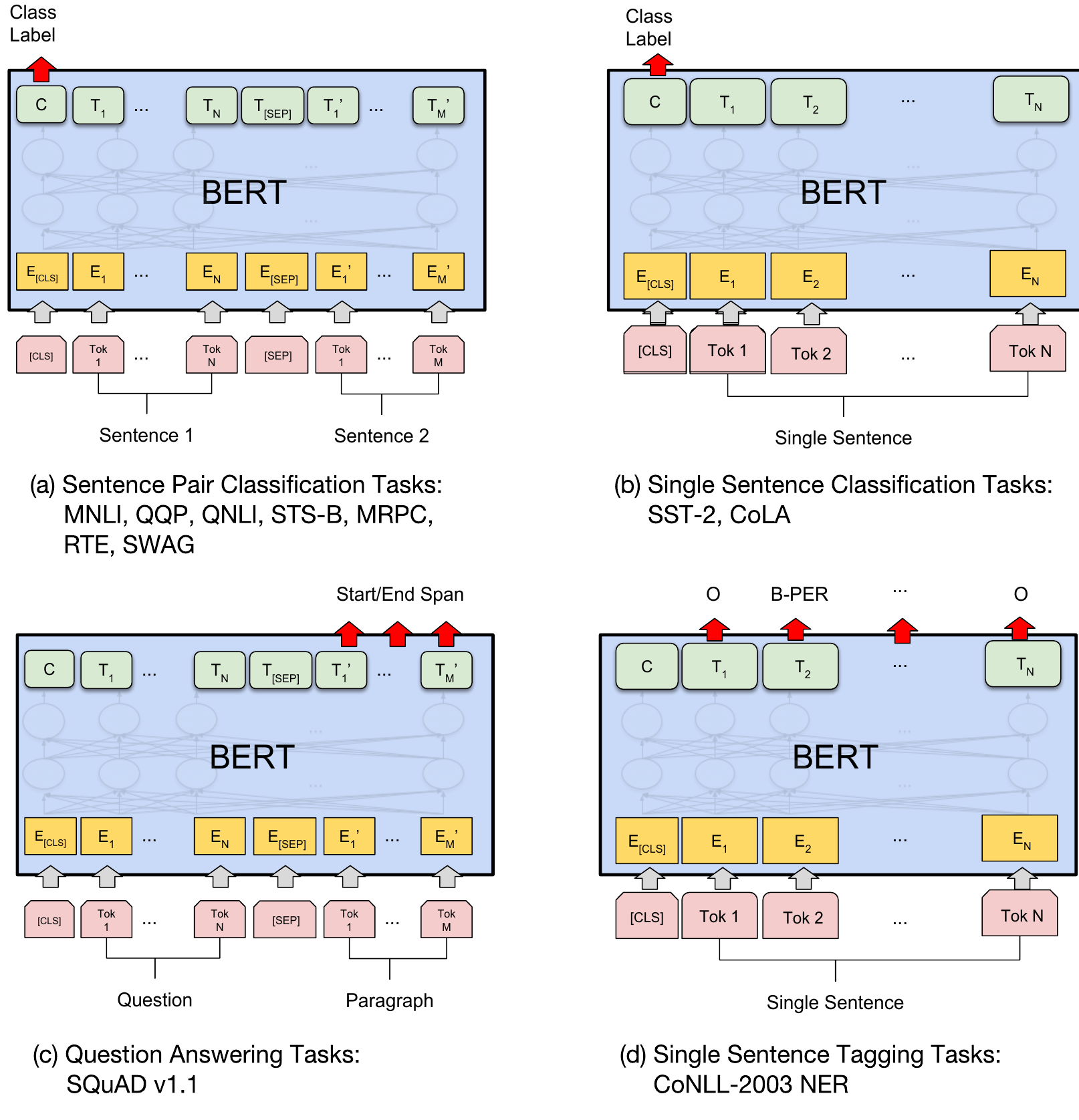
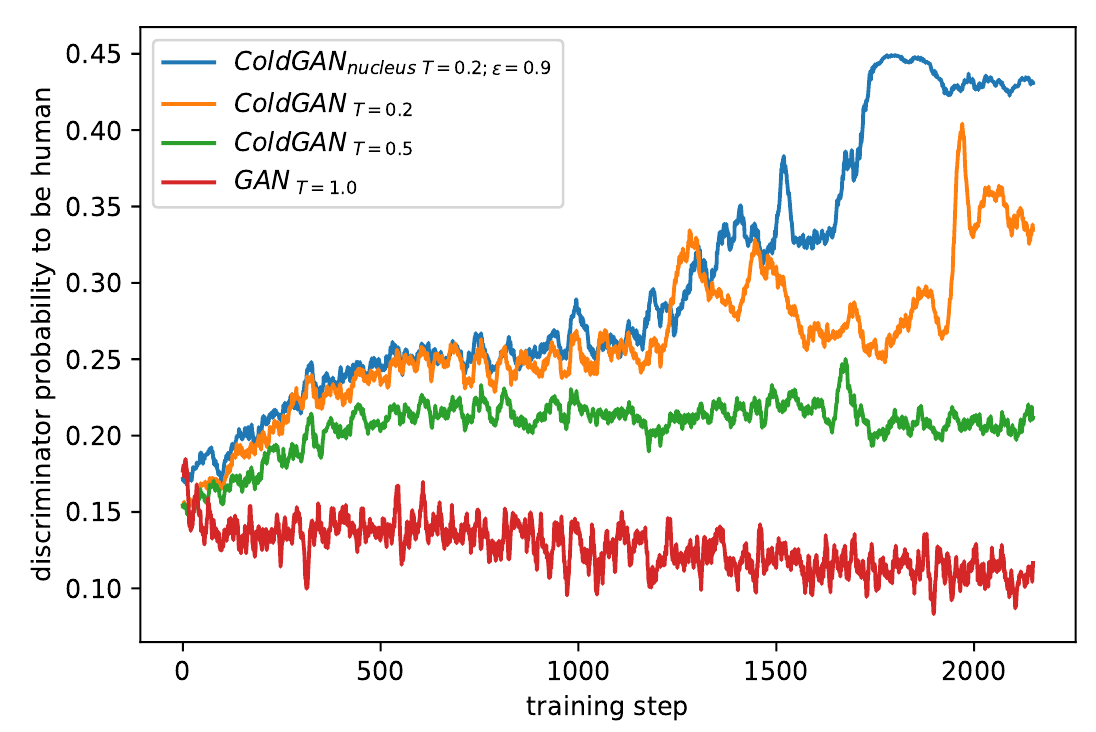
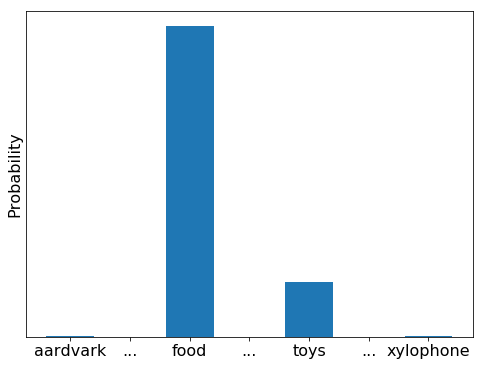
est-sur(le chat, le toit)
Équipe MLIA (LIP6 - Sorbonne Université)
div MLIA : Machine Learning and Information Access
10 permanents
Thématiques
- Apprentissage de représentation et "deep learning"
- Données structurées
- Apprentissage par renforcement
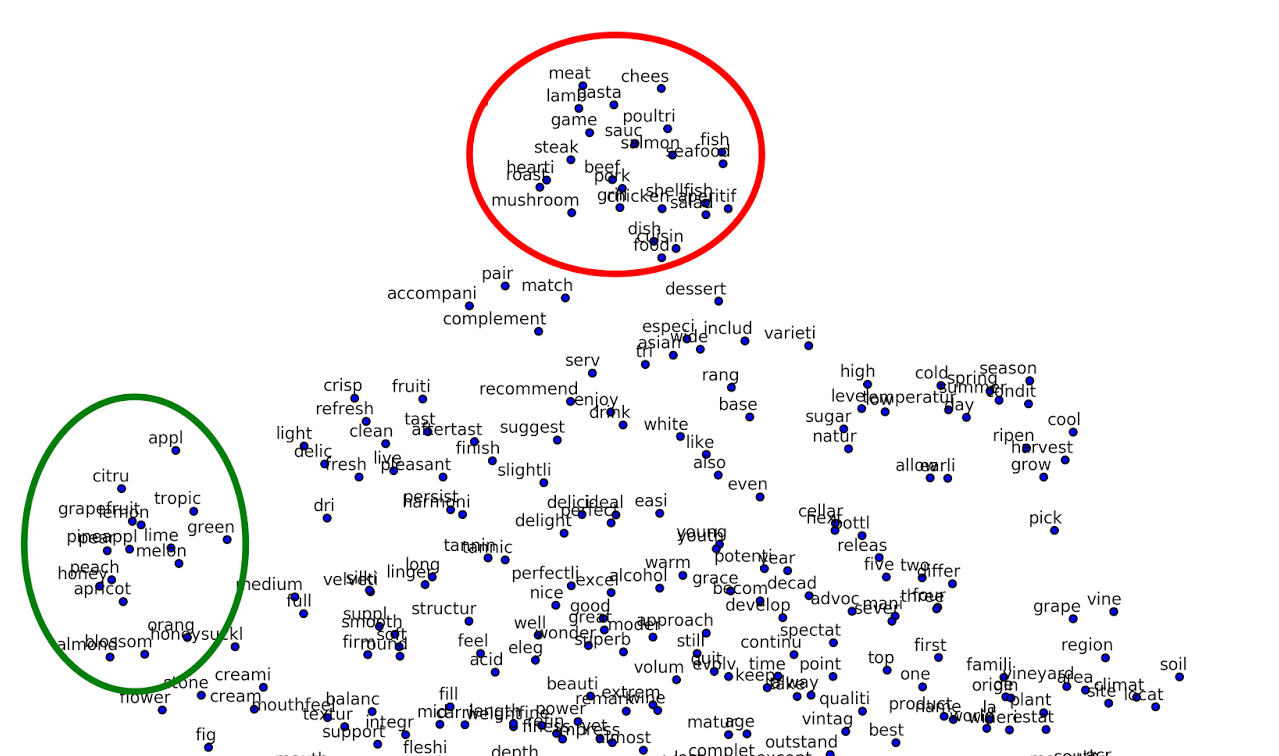
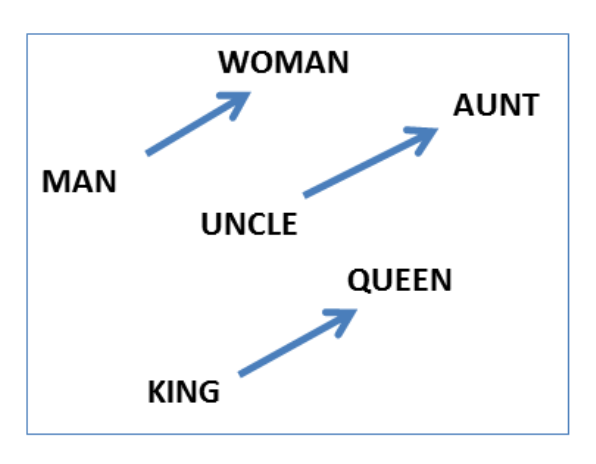
est-sur(le chat, le toit)(1.2 3.1 -1.2 .... 5.3) $\in \RR^n$Plus précisément, on se place dans le cadre des réseaux de neurones



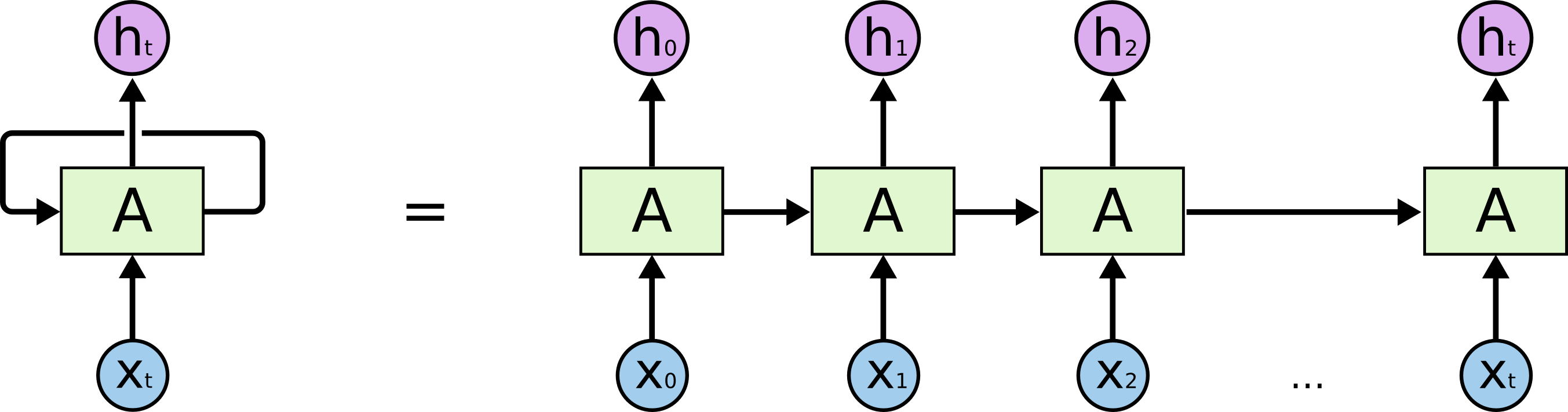

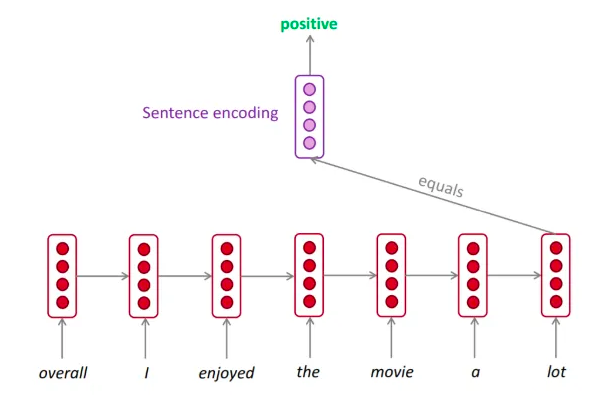

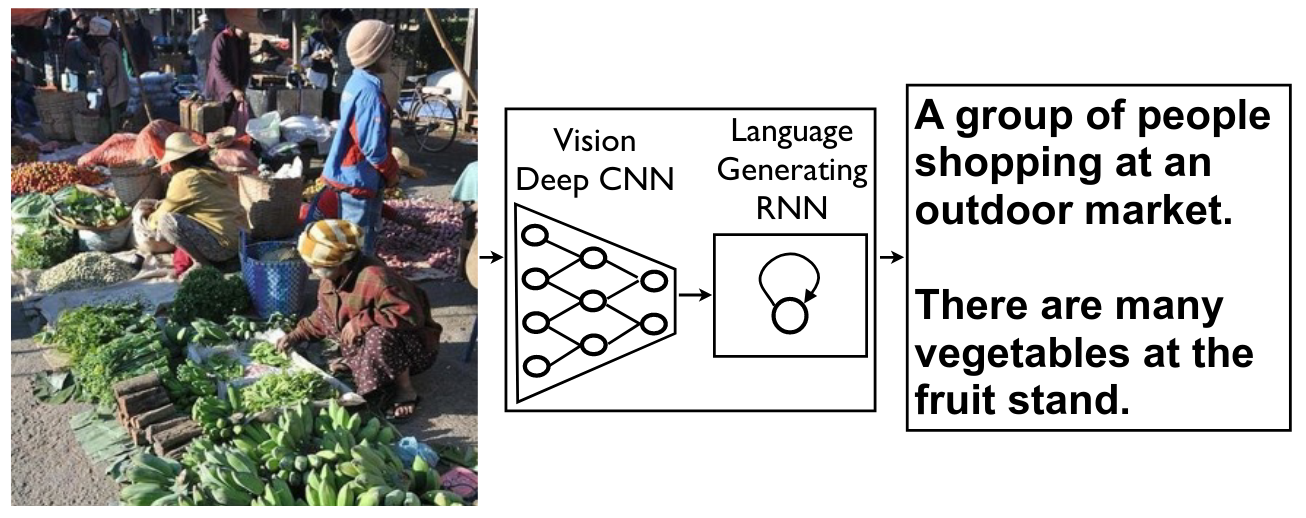
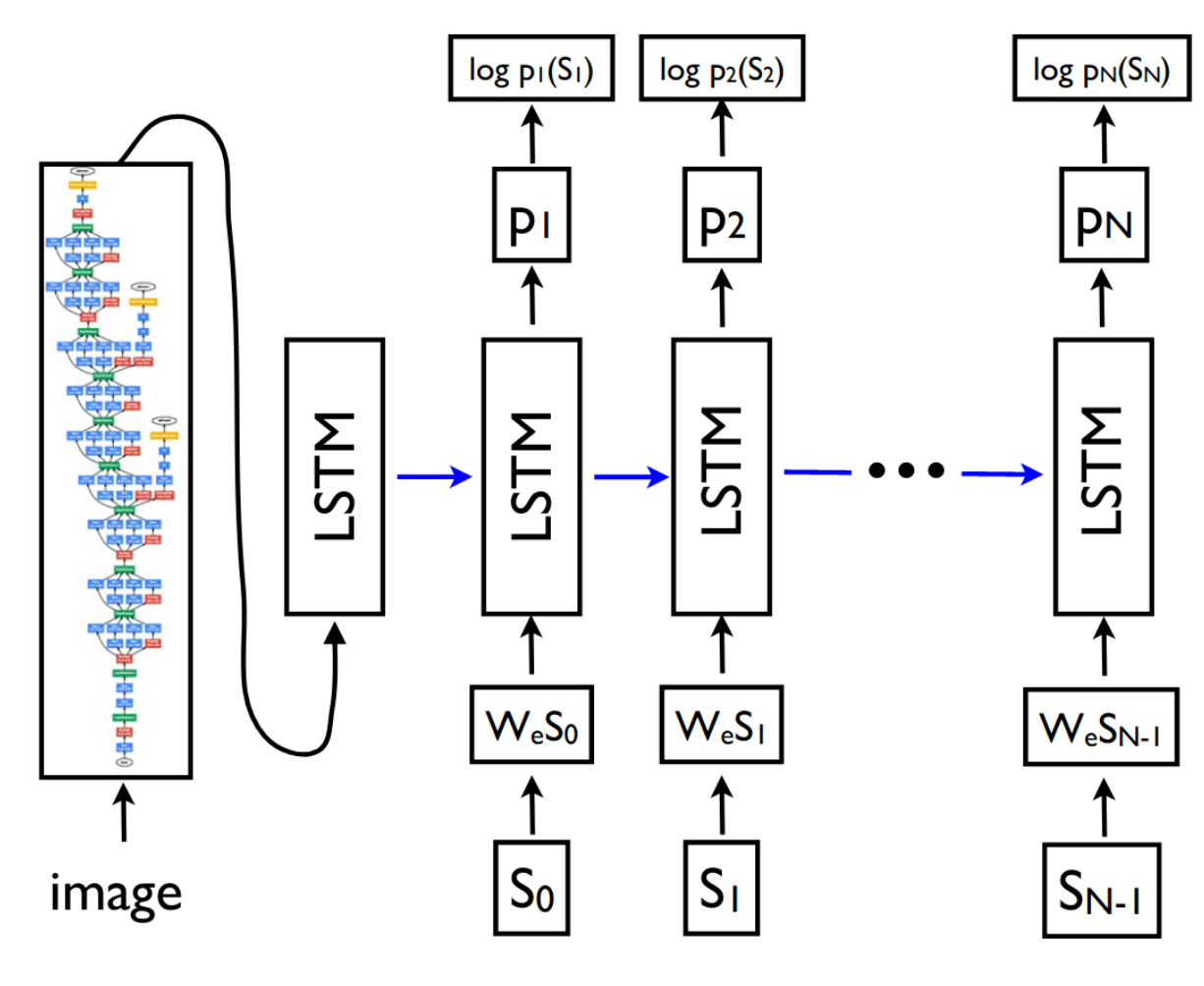


[CLS] ▁les ▁chats ▁sont ▁des ▁f éli dés [SEP]Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]Label = IsNextInput = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]Label = NotNext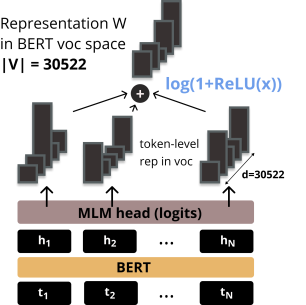
[MASK]J'ai faim [SEP] [MASK]J'ai faim [SEP] I [MASK]J'ai faim [SEP] I am [MASK]J'ai faim [SEP] I am hungry [MASK]